
Image: Freepik
By Mariana Meneses
In today’s digital era, data plays a crucial role in shaping business decisions, marketing strategies, and customer engagement. But when data quality fails, the consequences can be severe.
For example, in 2022, Equifax issued inaccurate credit scores for millions of consumers, leading to loan rejections and lawsuits; Uber miscalculated driver payments for years, forcing tens of thousands of drivers to absorb lost income before the error was corrected; and in 2018, a data entry error at Samsung Securities accidentally distributed $105 billion worth of phantom shares to employees, causing market chaos. As the number of data points businesses rely on grows, so does the risk of inaccuracies—quietly undermining even the most sophisticated systems.
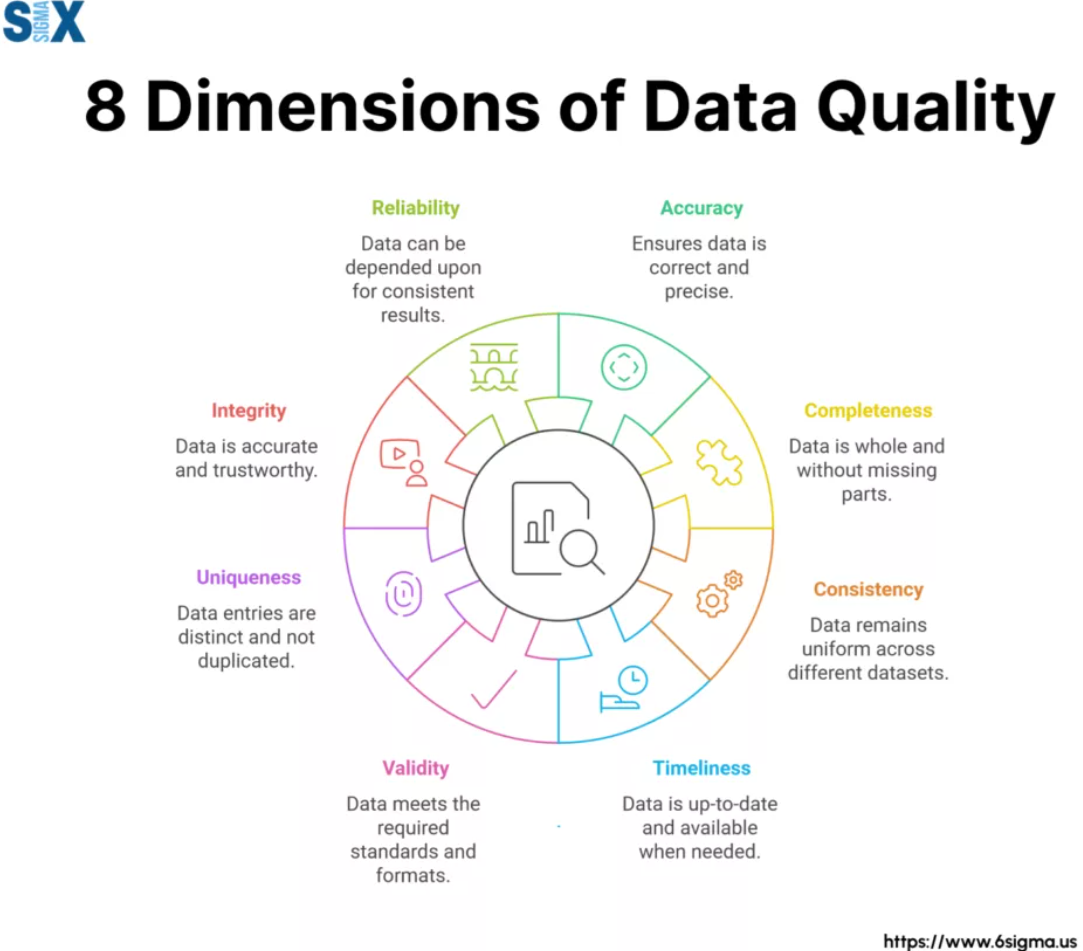
Dimensions of Data Quality. Credit: Six Sigma.
High-quality data—defined by dimensions such as completeness, accuracy, consistency, timeliness, validity, and uniqueness—is essential for effective decision-making, operational efficiency, and maintaining public trust. According to the U.K. Government’s Data Quality Hub, poor data quality leads not only to direct costs like operational errors and wasted resources, but also to longer-term risks including reputational damage and missed strategic opportunities. They report on estimate that organizations may spend between 10% and 30% of their revenue dealing with data quality issues.
Recent industry reports add that poor data quality can consume up to 40% of data teams’ time and cause hundreds of thousands to millions of dollars in lost revenue. Traditional practices—relying mainly on manual checks and static rules—are increasingly insufficient in the era of big data and AI, where real-time monitoring and proactive data management have become critical.
Most of the spotlight in artificial intelligence has been on building ever more powerful models—but what if the real bottleneck is the data itself? As machine learning spreads across sensitive domains like healthcare, finance, and public policy, the quality of the data feeding these systems becomes a critical, yet often overlooked, factor. Inconsistent formats, missing values, and mislabeled examples can silently erode the reliability of predictions.
A growing movement in the AI community argues that to build truly trustworthy systems, we need to shift from model-centric to data-centric thinking.
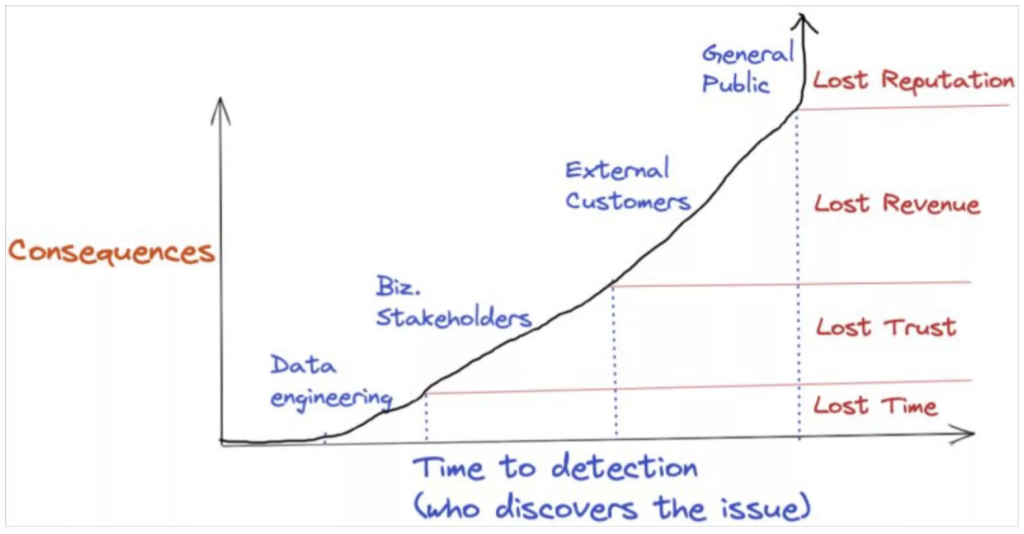
Consequences of poor data quality. Credit: Monte Carlo Data.
That’s exactly what a team of researchers set out to explore in one of the most comprehensive studies to date on data quality in machine learning. Published in the journal Information Systems in 2025, the paper by Sedir Mohammed, from the University of Potsdam, Germany, and colleagues systematically tested how different types of data flaws—like missing entries, mislabeled examples, or duplicated rows—affect model performance. Spanning 19 algorithms, 10 datasets, and nearly 5,000 experiments, their work offers rare empirical insight into how vulnerable today’s AI systems are to the imperfections of real-world data.
The researchers focused on six specific dimensions of data quality: completeness (how much data is missing), consistent representation (e.g., whether “NY” and “New York” are treated as the same), feature accuracy (how close values are to the truth), target accuracy (whether the labels or outcomes are correct), uniqueness (absence of duplicate entries), and class balance (how evenly samples are distributed across categories). To simulate real-world problems, they designed custom “polluters” that systematically degraded each dataset along these dimensions. They then tested how models responded when the corrupted data appeared in the training set, the test set, or both.
The results were striking. Some types of data issues—especially incorrect labels and missing values—had an immediate and often severe impact on model performance. Even small amounts of label noise in the training data caused many algorithms to falter, with some deep learning models proving particularly sensitive. Interestingly, models were often more robust to duplicates or inconsistent formatting, and in a few cases, exposure to poor-quality training data even helped models better handle noisy test data.
Overall, the study confirms what many practitioners suspect: even the best models can’t compensate for flawed data.
Image: Freepik
Beyond the technical insights, the study delivers a clear message for anyone building or deploying AI: data quality is not a minor detail—it’s a foundational concern.
Investing in better data can yield greater improvements than swapping one algorithm for another, and because different models respond differently to different kinds of data problems, there’s no one-size-fits-all fix. The authors’ release of open-source tools and datasets enables others to test how their own systems might behave under messy, real-world conditions—an essential step toward more reliable, transparent, and trustworthy AI.
Industry leaders like IBM emphasize the importance of distinguishing data quality from related concepts like data integrity and data profiling. While data quality assesses whether information meets criteria like accuracy, completeness, and timeliness, data integrity focuses on secure and consistent storage, and data profiling refers to the process of examining and cleaning data to uncover issues before they affect operations. Neglecting any of these areas can have serious consequences—the IBM article reports on estimates that poor data quality alone costs companies an average of $12.9 million annually.
The study by Mohammed et al. (2025) also reflects broader anxieties about AI’s role in creative and technical work. A recent survey highlighted in Wired Magazine captures the mood among software engineers: while some fear that AI will replace them, most see it as a powerful assistant and not a replacement. “AI is more like a hyperefficient intern—useful, but clueless,” or “If AI does eat programming, I’ll just switch to debugging AI.”
Whether AI becomes a job killer or just a job shifter, one thing seems clear: its usefulness will depend not just on the cleverness of its code, but on the clarity of its data. While Mohammed et al. focus on how flaws in static datasets affect machine learning performance, recent research highlights the importance of maintaining data quality in real-time environments—a growing challenge as AI systems operate on continuous data streams.
A 2024 study published in the International Journal of Medical and All Body Health Research (pdf) by Hanqing Zhang, from Trine University in the U.S., and co-authors explores this frontier. The authors propose a deep learning system that monitors data quality and detects anomalies as data flows through large, distributed networks—like those used in IoT sensors, financial systems, or internet traffic. Their system uses adaptive neural networks and parallel processing to keep pace with high-speed data, achieving nearly 98% accuracy and processing over a million events per second with minimal delay.
The findings suggest that for AI to remain trustworthy in live environments, data quality must be managed not only before training but continuously as the system runs.

Image: Freepik
The push for better data quality also has urgent implications in high-stakes fields like healthcare, where information must be both accurate and secure.
A 2024 study published in the journal Expert Systems by Sushil Kumar Singh, from Marwadi University in India, and colleagues introduces a new technique for evaluating the quality of healthcare data using what they call Mutual Entropy Gain, which is a method grounded in information theory. Their system identifies the most meaningful features in medical datasets to distinguish high- from low-quality data, even when only a fraction of the full dataset is available. This not only boosts efficiency and reduces storage needs, but also enhances patient data security. In a field where errors or inefficiencies can cost lives or lead to data breaches, their approach offers a way to ensure quality while managing resources responsibly.
With advances in real-time monitoring and large-scale processing, studies like this reinforce a growing consensus: investing in data quality isn’t just a technical choice, it’s a strategic and ethical one.
That challenge is intensifying as AI-generated content increasingly feeds back into the training loop and introduces new risks of distortion, redundancy, and self-reinforcing bias. A 2024 study published in Nature by Ilia Shumailov, from the University of Oxford, and colleagues warns that this recursive process can lead to “model collapse” — a phenomenon in which the statistical richness of original, human-created data erodes, along with a model’s ability to generalize or retain nuance (The broader cultural risks of model collapse, including its impact on human creativity, have been highlighted by The Quantum Record in a March 2024 editorial).
Their findings show that when models are trained on content generated by other models, subtle signals in the data distribution begin to vanish, degrading performance in ways that are difficult to reverse.
In other words, the more AI learns from itself, the more it risks mistaking imitation for insight.
As generative systems become further embedded in the infrastructure of knowledge and decision-making, preserving genuine, diverse, and high-quality data is no longer just a technical concern—it’s foundational to the future of machine learning itself.
As AI systems move from prototypes to public infrastructure, the conversation about model performance must expand to include the less glamorous, but far more consequential, question of data quality. These studies show that the integrity of outcomes depends not just on breakthroughs in modeling, but on the everyday decisions about what data is collected, how it’s labeled, and whether it truly reflects the world it claims to represent.
In that sense, the future of trustworthy AI may rely less on what we can automate and more on what we choose to pay attention to.
Craving more information? Check out these recommended TQR articles:
- Digital Sovereignty: Cutting Dependence on Dominant Tech Companies
- Does Time Flow in Two Directions? Science Explores the Possibility—and its Stunning Implications
- Do We Live Inside a Black Hole? New Evidence Could Redefine Distance and Time
- What’s Slowing the Expansion of the Universe? New Technologies Probing Dark Energy May Hold the Answer
- The Corruption of Four-Dimensional Humanity with Two-Dimensional Technology
We would love to know what you think about The Quantum Record and articles like this.


