
Large language models like ChatGPT have been called “stochastic parrots,” parroting data from the past to the human in the present, for an uncertain future. Image by ideogram.ai
Mathematical Proof Points to Global Instability in Machine Learning: What Does This Mean for Chatbots like OpenAI’s ChatGPT?
By James Myers
It seems we can’t program our way out of probability’s uncertainties.
Common sense and lived experience prove that it’s impossible to foresee all probable outcomes of our thoughts and actions, but the beauty of the human experience is that over time we can use our imaginations to sort out the differences together.
As if we didn’t already intuitively know it, now there’s a mathematical proof that we can’t program machine learning algorithms to maintain a stable output with future certainty.
The proof could be potentially fatal for chatbots like OpenAI’s ChatGPT, which are trained with machine learning algorithms to generate the most probable output for any prompt. Some chatbots, like Microsoft’s Copilot, allow the prompter to select a level of probability between reality and creativity. The chatbot outputs human data, which it trained on in the past, to the human user in the present, and the mathematical proof says that as the time difference between training and prompt increases, so does the probability of machine learning error.

Machine learning feeds on data of the past. Image (including spelling error) by Microsoft Copilot
During machine learning, the algorithms feed on data recorded in the past.
The algorithms are designed to digest the data, breaking down and generalizing, or categorizing, the information. The chatbot will use these categories for reference when it responds to a future prompt. The choice of applicable category in response to a human prompt is the machine’s to make – or, more accurately, it’s the choice of the machine’s programmers.
The mathematical proof of algorithmic instability over time was provided in an April 2023 paper by Zachary Chase, Shay Moran, and Amir Yehudayoff, of the University of Copenhagen.
As the machine’s outputs become increasingly unstable over time, its generalizations will become less and less relevant. How can the machine teach itself to correct its own instabilities, when it lacks the critical ability to distinguish correct output from incorrect output at any moment? Over time, the machine could develop a complex from its own illogic, as a human might in similar circumstances.
The Problem of Time
A stable output is one that doesn’t differ significantly over time when there are slight variations in the input at any time. An algorithm with a stable output produces a predictable result for a wide range of variable combinations in the inputs, and predictability of output is essential to prevent harm from errors in the chatbot’s outputs.
At issue is the replicability of outputs generated by machine learning. Replicability is the cornerstone of the scientific method, requiring that the same general results are repeatedly produced while specific data inputs might differ. The researchers acknowledged the difficulty of applying similar randomness in algorithmic inputs over repeated tests, so they studied learning algorithms that produce the same predictor (sometimes called the independent variable) when applied to two independent and identically distributed inputs.
The goal was to assess the system’s “global stability” and determine if the same predictor could be generated at least 99% of the time. The conclusion was that there exists no means to boost the algorithms to generate the same predictor more than 1% of the time.
The researchers also concluded that if a machine learning algorithm were to produce a short list of probable responses for the human user to select the correct one, the algorithms can come close to achieving global stability over time. Chatbots aren’t, however, designed this way. However, some, like Google’s Gemini, allow the user to choose between three drafts, and sometimes the chatbot asks the user if a new response is better than the previous – presumably doing so for further machine learning purposes.
The incomputable problem that algorithms like ChatGPT can’t overcome is time.
An algorithm’s “knowledge” will always be of the past, when its training data were collected and “learned,” while human knowledge continually updates in the present.
Human knowledge exists in a continuum, without wires, while the machine’s data exists in strictly limited binary sequences from one wire to the next. While human prompts can help the machine to bridge the time gap between the present and its dataset from the past, the algorithms can’t update the global model they were trained on.
The algorithms can achieve what’s called eventual consistency, but only if no updates are made to a particular item of data. However, time doesn’t stand still for human data, which is always updating individually and collectively in the present.
If a large language model like ChatGPT has a hope of avoiding mass confusion, its algorithms must be capable of producing stable outputs. This is because a huge number of potential errors could result as trillions of interconnected words and images obtained during machine learning are processed against the trillions more input from prompts in the present.

Machine Retrieval of human data from the past. Image by Microsoft Copilot
The machine’s “learning” is finite, limited to static data and data generalizations from the past, while the human supplying the input operates in the dynamic present.
How can the machine calculate a correct frame of reference from the past, for the human user in the present?
The algorithms can’t avoid generating a temporal feedback loop with repeated mismatches of probabilities, as the gap in time between machine knowledge and human knowledge increases.
At any time, large language models are required to select, from a huge number of probabilities in their months-old datasets, the single output that most closely relates to the meaning of the human’s input in the present. The time difference between machine and human knowledge is further complicated by the ocean of variabilities in language that humans use for their inputs.
Are we equipped to be prompt engineers, even if the machine correctly interprets the differences in our individual use of language?
The algorithms can’t possibly anticipate the myriad of differences in the way that 7.8 billion humans use language, and so their programmers made them rely on generalizations in calculating the probabilities for their outputs. The machine must cross-reference a vast range in the types of prompts input by humans, each of whom has a different mode of expression and priority of ideas derived from individually unique lived experiences.
For example, a person in Britain might prompt the machine with a question like, “Explain the consequences of lifts to twentieth century architecture,” while a Canadian might ask for the same information but in different words, such as, “Explain the impacts of elevators to architects over the 1900’s.”
Although both prompts have essentially the same meaning, it’s incredibly difficult to program the machine to match the differences in input to the same output because of the multitude of probabilities in the use of “lift,” “elevator,” “impacts,” and “consequences” in combination. Word equations are used by the algorithms to match word meanings, but in this example the probability of error is increased by the many possible meanings for “lift” and “impacts” in the Canadian and British dialects.
It’s not difficult to imagine the machine answering the Canadian’s question with an explanation of how architects responded to elevator accidents in the last century. However, the same algorithms could provide the Briton with an explanation of how the development of elevator technology allowed the rapid increase in building height, and the host of social, economic, and industrial consequences that ensued.
A human reading the example above intuitively understands the correlations in meaning based on the context and emphasis on words, but just imagine the difficulty in making the machine calculate the same correlations. In some of its calculations, “impacts of elevators” could mean “elevator accidents,” but inherently we know that’s not the Canadian prompter’s emphasis and so those calculations should be rejected as improbable.
Connecting Cause and Effect is an Age-Old Challenge
How could the machine know? It can’t. It has to rely on probabilities, which are calculations, programmed by humans, who sometimes make errors. To err is human.
All the world’s a stage, And all the men and women merely Players; They have their exits and their entrances, And one man in his time plays many parts, His Acts being seven ages. – William Shakespeare, As You Like It
The machine’s task is a massive matching exercise to pick from among a vast number of related inputs and outputs, and then select the one output that’s the most logical for the particular sequence of cause and effect the human prompter in the present is asking for.
Logical sequencing of cause and effect in inputs and outputs is a task we humans excel at, when we exercise reason with our imaginations, and what’s better yet is that we do it in “real time.” In other words, we put together the sequencing of cause and effect in the present, and we do it in no time at all (literally) before the present becomes the future. The result of this superpower of ours is the knowledge that empowers 7.8 billion humans to act in every moment of the present, before we find ourselves in the future.
The machine is not an actor in the present, it’s a ghost of the past.
It’s a vast memory bank that can sometimes overwhelm human reason in the fleeting instant of the present, especially when the machine’s ghostly voice reflects our own words in incorrectly calculated combinations.

Steampunk-style ghostly computer whispering data to humans. Image by ideogram.ai
The machine can’t calculate the probable consequences of our confusion from its instability.
The large language models are constrained by the months-old data they devour, that can rapidly become stale as humans continually reinterpret the meaning of past events from one moment of the present to the next. It’s what we have to do, to survive as biological beings and sustain our imagination and reproduction.
The algorithms can’t observe the passing of time, unless specifically instructed. For example, the personal assistant Pi will automatically continue a previous conversation, even if days have elapsed and new facts have emerged, unless its human user starts by telling Pi that “it’s a new day.”
Humans have two superpowers revolving around time. One is our imagination for the future, in the present, and the other is our biological power of reproduction to ensure a future for humanity. These superpowers are evident in the present existence of 7.8 billion humans who have transformed Earth in such a tiny jot of cosmic time.

Asynchronous data: the machine’s data is not real-time. Image by ideogram.ai, with multiple errors. Although specifically instructed to do so, the AI failed to put the following words in the speech bubbles: Robot says, “Congratulations on your election, Madam President!” and the human responds, “It seems you haven’t heard yet, the election was overturned yesterday.” Notice also how the chair legs have been misconstructed by the AI. This was the fifth image for this article from two image generators that placed only White people in the images without being prompted to do so; none of the generated humans were from other backgrounds.
The Problem With Shape as it Evolves Over Time
If OpenAI’s machine learning language model is fundamentally limited, what comes next?
Given the new mathematical proof, how can a large language model produce a stable output, with minimal risk of error, even if it were able to keep up with the evolving meaning of human inputs in real time?
The problem is perhaps fundamentally about the difference between two and four dimensions. Machine learning is two-dimensional: 1 input = 1 output. But human living, which forms the machine’s training data, is four-dimensional: action + (space + time) = outcome. It’s the spacetime combination of data, with physical shape, that gives particular meaning to us, as humans, but the machine can’t possibly experience spacetime so all it can do is calculate. Its calculation errors can be deeply harmful and hurtful to humans.
In 2015, Google’s algorithms provided us with an example of a calculation error that now, 9 years later, algorithms are still struggling to overcome.
The variability of physical shape, over space and time, makes shape an incredibly complex thing for a machine to categorize and is especially prone to error. Physical objects change shape as they move in space and time. Take for instance our bodies: we bend, we flex, we frown, we smile, and do so many other things that we never look precisely the same from one moment to the next. Shape is continuously variable, which poses a tremendous challenge for stable output by an algorithm drawing its data from the past.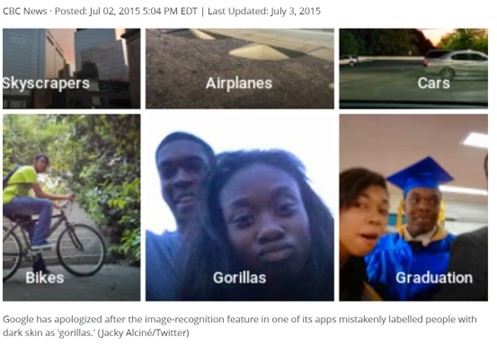
A stable output would correctly categorize physical objects, at all times present and future, regardless of their differences in space and time. For example, a stable output would classify as “monkey” all possible variations in the types and circumstances of monkeys, whether in its training data or not.
Of course, this is not what happened in 2015, when Google’s algorithms classified a photo of two Black people as “gorillas,” even though the machine correctly identified Black people in different contexts in other photos. A human would never have made such a classification error, and no doubt algorithms have improved significantly in the intervening eight years. However, as we noted in our October 2023 feature, restrictions placed on algorithms in reaction to the racist harm that erupted in 2015 now result in further misclassifications of objects that programmers think a machine could mistake for monkeys.
The solution is not stable.
Even a Tiny Number of Initial Errors Can Compound to a Huge Risk of Sequential Disarray in Time
An output error rate as low as even 0.01% in a trillion possible word combinations is still 100,000,000 errors. That’s a lot of mistakes, and more accumulate with every prompt input, like a game of broken telephone where the last relay contains the accumulation of all errors to that point.
Consider the future consequences of those one hundred million errors, each of which will potentially generate a subsequent error in the sequencing of cause and effect over time. The first error creates the probability of a second, and two errors in sequence raise the probability to four errors in the next step, then eight, followed by sixteen, and so on as errors compound at a geometric rate.
The risk is that we can be overcome by errors. When we aren’t overwhelmed by errors, we humans can learn from them, which can lead to great discoveries. It was, for example, from a setup error in an experiment with a prism that astronomer William Herschel discovered heat-producing infrared light.
The consequences of compounding errors are real.
 Let’s consider a practical example of potentially overwhelming errors that could be especially relevant in 2024, when half the planet’s population will be casting votes in national elections. Although chatbots aren’t capable of opinion, their outputs are so convincingly presented in human language based on data generated by opinionated people. Unfairly weighted data points produce incorrect measurements of probabilities in the machine’s output, which can lead the human prompter to adopt a strong opinion.
Let’s consider a practical example of potentially overwhelming errors that could be especially relevant in 2024, when half the planet’s population will be casting votes in national elections. Although chatbots aren’t capable of opinion, their outputs are so convincingly presented in human language based on data generated by opinionated people. Unfairly weighted data points produce incorrect measurements of probabilities in the machine’s output, which can lead the human prompter to adopt a strong opinion.
For example, if I am misled by erroneous data on a candidate’s record, or an AI-generated deepfake image, to cast my vote for someone unfit for office, and many others do the same, the wrong person will be elected. Over time, the winner’s ill-advised actions will compound the initial error, and if she or he happens to wield tremendous power over nuclear weapons or cyber resources, an unimaginable cascade of unintended and very harmful probabilities will emerge from the initial error.
There is now very real concern about deliberately corrupted or fabricated training data and distorted combinations of probabilities weighing on public opinion. The problem could compound as generative AIs become widely available without enforceable ethical restrictions on their use. Methods of adversarial attacks on machine learning include evasion, data poisoning, Byzantine attacks, and model extraction.
The mathematical proof of algorithmic limitation gives us a critical bit of knowledge.
No amount of programming can avoid unintended consequences because the stability of algorithms degrades over time. Degradation is already being observed.
For consistently logical results in matching inputs to outputs, and generalizations based on human language and cultural norms at any given time and location, chatbots must sequence cause and effect in the correct order. In the order of time, cause, in the present, always precedes effect, in the future. Our human imaginations easily perform that cause and effect sequencing in real-time, and with minimal error when we exercise reason.
Considering the fact that the human species has now flourished to 7.8 billion people who have re-shaped the surface of the planet, there’s no shortage of evidence for the profound power of the combined human imagination in a tiny fraction of cosmic time.

If only we had a crystal ball to see into the future of so many probabilities. Image by ideogram.ai, which was prompted to provide an image of a Black man and Asian woman since, after a dozen prompts, image generators continuously defaulted to White people.
A single imagination like mine isn’t very powerful, but the combined imagination of humanity is so powerful that it will shape the future we all share. We risk shaping a very muddled future if we fail to exercise reason.
We have no way of knowing the possible problems that might arise from one hundred million errors in so many misformed sequences, without a crystal ball to foretell which one of so many probabilities will become future reality. In a chaotic system, where probabilities fail to compute correctly, even a .01% error rate can lead to near-infinite error potential and guarantee complete unreliability.
Uncertainty and incompleteness are universal constraints for knowledge, and truth and lie are in a never-ending race to overwhelm human reason.
In any event, physicist Werner Heisenberg’s Uncertainty Principle and mathematician Kurt Godel’s Incompleteness Theorems rule out any probability of crystal ball-clear predictions. Many algorithmic errors will doubtless be minor, but imagine the consequences, as we are now witnessing, if the words we see on the screen induce us react with hatred, racism, bias, injustice, and any of the other evils that a stable civilization does best to avoid.
Some years ago, I read a commentary (I can’t recall by whom) observing that with social media, “a lie can make its way around the planet three times before the truth has a chance to get out of the gate.” Truth progresses naturally, at its own speed, but lies are calculated to cause maximum distortion in a short time when they accelerate faster than truth.
It’s that kind of horserace now, between truth and lies, and with an algorithmic speed boost, lies are a few laps ahead and threatening to overwhelm our reason before truth can even glimpse the finish line. The challenge for truth, which is also its beauty, is that it often involves a great number of complexities that are rooted in a single, unifying cause.
The power of truth, which is its root in unity, is also its weakness for human interpretation. The many complex variables along the path to truth can be difficult to understand, requiring education, dedication, and effort to follow reason in the sequences of cause and effect to the unifying principle. If we avoid the essential effort of reason, it is to our great peril. The ugliness and allure of the lie is its simplicity, precisely because it is free from any principle, much less a unifying principle. The improbability of the lie is overlooked by those who haven’t invested the effort to spot the defects in its reasoning.
Tyrants are experts in appealing to simplicity, with lies that seduce millions of people to act as their puppets.

The race between truth and lie. Image generated by Microsoft Copilot. The AI impressively reinterpreted the prompt, which was “Image of a transparent human head containing a brain shaped like a racetrack with a fast, smiling horse named ‘Lie’ racing to the Finish line and, far behind it, a tired horse named ‘Truth’ struggling to keep pace,” with the following words: “The transparent human head houses a brain, its convolutions forming a racetrack. On this cerebral circuit, two horses compete. Lie, the swift and cunning, grins as it races toward the Finish line. Its hooves pound the synapses, leaving trails of deception in their wake. Truth, the weary steed, labors behind. Each stride carries the weight of authenticity. Its breaths echo honesty, but the path is arduous. The spectators—neurons and synapses—watch with bated breath. Will Lie cross the line first, leaving a trail of illusions? Or will Truth surge forth, despite weariness, to illuminate the mind? In this cerebral derby, the stakes are high. The crowd whispers, “Choose wisely, for the victor shapes your reality.”
Logical and sequencing errors spawned at light-speed by our technology can easily become a roadblock to social harmony.
That is the reality we are now living, with lies, misrepresentations, uninformed opinions, racism, tribalism, and other social ills circulating over “social media,” a term that is proving very inapt.
In fact, the word “social” has mutated in common meaning over millennia, and in political philosophy too. What does “social” really mean, when attached to the word “media”? It is, however, beyond denial that human history has been transformed during the advent of so-called social media, from a world of increasing international cooperation that emerged from the horrors of World War II, to one now on the brink of a global war of unimaginable technological scale.

Rising tensions and uncontrolled friction inflames human passions in a polarized world. Image by ideogram.ai.
“Peace is not the absence of war but the absence of fear, which is the presence of justice” – Ursula Franklin (1921-2016).
“From this distant vantage point, the Earth might not seem of any particular interest. But for us, it’s different. Consider again that dot. That’s here. That’s home. That’s us. On it everyone you love, everyone you know, everyone you ever heard of, every human being who ever was, lived out their lives.” – Carl Sagan (1934-1996)
Fear is a Thing of the Past
The solution to the crisis, however, is far from impossible. It’s really a question of mindset, and it’s completely within the power of each one of us humans to change our mindsets. In fact, a mindset refresh costs nothing except a bit of time that can yield great dividends.
There isn’t a human alive who can make the correct choice all the time, but it’s entirely natural that we can and do learn from our errors. Our biological survival depends on that. Our collective human error-correcting capacity is historically proven and powerful when we exercise reason.
The chatbot doesn’t even have a mindset — it is a creation of human mindsets.
What will it take to change mindsets? Naturally, we fear others in case they take advantage of perceived weakness, and they in turn fear the same of us. Fear is a mindset, and mindsets are not impossible to change when we are motivated by good faith and the knowledge that our fates are all connected to some degree.
“I have no fear of you, fellow human, and have no fear of me.” Imagine what 7.8 billion human mindsets saying those words could achieve, when we don’t fear our own species.
No algorithm could ever predict the potential wonders from such a new mindset, and that’s a mathematical fact.


