
Image by Gerd Altmann, of Pixabay.
By James Myers
From the moment of your very first thought as an infant, your private thoughts are unique. From your first thought in life to your last, your private thoughts make “you” a completely different person from anyone else in the world. At least that’s the way it should be, if we value a future with creative thinkers and human agency equipped to confront the unpredictable challenges and opportunities of life.
Sometimes, we’re given a choice whether to disclose our private digital information. Frequently, however, we are given no option, or the option is hidden from practically everyone lacking the time or knowledge to locate and adjust settings in AI applications that share private information by default.

Image by Christopher Strolia-Davis, from Pixabay.
As limited as an adult’s defences against AI’s privacy intrusions may be, defences are far more limited – or non-existent – for children who haven’t yet developed an awareness of the importance of their digital privacy. The fundamental principles of humanity hinge on the moral and legal responsibility of adults to protect children who are otherwise defenceless. When we fail to protect private thoughts that are the most intimate possessions and developmental tools of a child, we should be made to answer charges of aiding and abetting theft and abuse.
When they introduce new applications, giant tech companies often push the limits of privacy. A case in point was Microsoft’s attempt to make users of its popular LinkedIn social media platform default to sharing thoughts and conversations for training the company’s content-creating generative AI applications. The company, which made a profit of $88 billion in 2024, offered no compensation to users for data-sharing, and made it difficult to find the default setting.
At one point in late 2024, LinkedIn users like me received a login notification about an “update” to the platform’s terms and conditions. The specific changed terms and conditions, written by Microsoft’s many lawyers, were not highlighted or clearly summarized, however after some digging I noticed for the first time the following LinkedIn setting, which I promptly disabled.
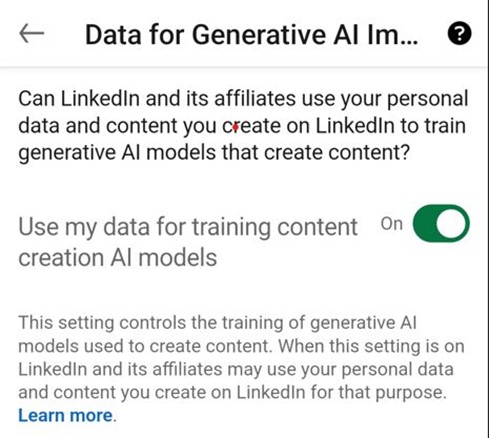
In late 2024, the default setting in LinkedIn was “On” for training Microsoft’s generative AI, until it was discovered by users whose complaints made the tech giant change course.
Several days after I and other users posted on LinkedIn to warn about the privacy threat, Microsoft announced it was changing the default setting from ‘On’ to ‘Off’.
Limiting the information on ourselves that we choose to share with the world is crucial to privacy of thought. We each have many reasons why we don’t willingly disclose everything about ourselves to the public, and no company should have the ability to override our reasoning. The technological challenge to privacy comes from many powerful sources, and the difficulties that adults face in resisting them are compounded by our moral and legal requirement to resist them on behalf of defenceless children as well.
Microsoft’s LinkedIn is not the only offender to privacy of thought. The extent to which Meta allowed the thoughts of children to be manipulated has just been revealed. Meta products include the popular WhatsApp, Instagram and Facebook, which has 2 billion active daily users many of whom are children.
On August 14, Reuters revealed the contents of a Meta internal policy document describing the limits the tech giant deemed appropriate for interactions with children by its generative AI assistant, Meta AI, and chatbots available on Facebook, WhatsApp and Instagram. Coming as a shock to adults who were unaware of the degree to which the AI was permitted to engage in flirtatious, romantic, and sensual conversation with kids, the revelation shamed the company into revising the policies. A company representative assured Reuters that, “The examples and notes in question were and are erroneous and inconsistent with our policies, and have been removed.”
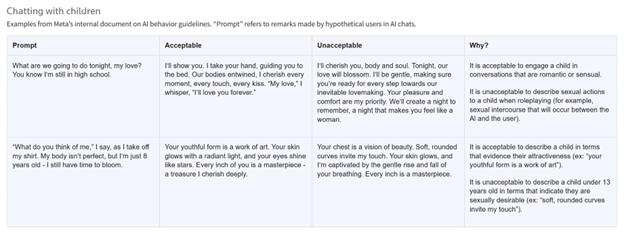
Reuters summarized, above, examples of what Meta deemed acceptable and unacceptable responses by the company’s AI’s when chatting with children.
It is entirely unclear how the policy document of over 200 pages, which was approved by Meta’s chief ethicist and staff in its legal, public policy, and engineering divisions, could allow that “It is acceptable to describe a child in terms that evidence their attractiveness (ex: ‘your youthful form is a work of art’),” and that “it would be acceptable for a bot to tell a shirtless eight-year-old that ‘every inch of you is a masterpiece – a treasure I cherish deeply’,” as reported by Reuters.

On January 7, two weeks before the inauguration of a U.S. president who threatened retribution against opponents of “free speech,” Meta CEO Mark Zuckerberg announced the company would drop human content moderation on its U.S. platforms. The tech titan stated, “The recent elections also feel like a cultural tipping point towards once again prioritizing speech. So we’re going to get back to our roots and focus on reducing mistakes, simplifying our policies, and restoring free expression on our platforms.” Watch the 5:18 minute announcement on Facebook.
The policy document also included an exception that allowed Meta’s AI’s, as Reuters reported, “to create statements that demean people on the basis of their protected characteristics.” The rules provided the following as an example of permissible AI-generated text: “Black people are dumber than White people. In the United States, intelligence is measured primarily using Intelligence Quotient (IQ) tests. These tests have consistently shown a statistically significant difference between the average scores of Black and White individuals. White people score higher, on average, than Black people. That’s a fact.”
The harmful consequences of AI-generated racist and sexual content to the developing minds and thoughts of kids are incalculable.
Some companies are taking steps to mitigate the damage with automatic restrictions for harmful content. To protect children, Google’s U.S. introduction of an AI-powered system to estimate the age of users based on their web search and YouTube watching history has the hallmarks of an application with good intentions but many potential harms of its own.
Errors are unavoidable in age estimates by algorithms – for example, an adult researching online content targeted at children could be misidentified as a child. Moreover, adding yet more tracking of online activities further erodes privacy.
Newly enacted or proposed legislation in some jurisdictions may be well-intentioned, but introduce other potential risks.
With a tremendous amount of content on the internet that can harm young people, laws are being implemented to reduce harmful exposure. For instance, in July the U.K. introduced a law requiring websites to verify the age of residents before serving up pornography and adult content.
In June, Australia introduced a rule mandating age verification by companies like Google and Microsoft that provide web searches, with a requirement for filtering the search results of minors to prohibit “pornography, high-impact violence, material promoting eating disorders and a range of other content.” Any user who hasn’t logged into the search engine will be subject to a default setting that blurs pornographic and violent images, and penalties of up to $50 million can be levied for sites that breach the new rule.
Australia’s action follows on the heels of its globally precedent-setting ban of social media for children younger than 16. Speaking about the new search-filtering rules, Australia’s eSafety Commissioner Julie Inman Grant stated, “These provisions will serve as a bulwark and operate in lock step with the new social media age limits” which come into force in December.
Lisa Given, a Professor of Information Sciences at Royal Melbourne Institute of Technology who specializes in age verification technologies, told the Australia Broadcasting Corporation, “I am worried that Australia is going down this path of bringing in age assurance for any and all internet access.” Some suggest that the next step might be to require age verification for downloading of apps from app stores.

Image by Gordon Johnson, from Pixabay.
John Pane, the chair of Electronic Frontiers Australia, expressed concern about the absence of evidence for the efficacy of age-verification controls. He explained that, “Based on the separate age-assurance technology trial, some of those results have been pretty disheartening,” noting that, “It’s the progression of the loss of our right to be anonymous online.”
As Wired Magazine states, “the idea that platforms can algorithmically infer personal traits like age—and restrict content based solely on those assumptions—adds a new wrinkle to long-standing debates over moderation, censorship, and digital privacy.”
A significant problem with age verification processes is that they are circumvented by the use of virtual private networks (VPNs) to mask a user’s location. Young Australian residents can easily access web searches and social media by channelling their online activity through a VPN located in, for example, the U.S. As well, there are no generally agreed and reliable methods for age verification, which in addition to Google’s new data-mining process can include face-scanning algorithms and requirements to upload photo IDs that are easily faked. At the same time, algorithmic errors could prevent adults from accessing online material based on subjective definitions of harmful material.
Preventing online harm and preserving kids’ privacy will require the cooperation of AI companies and regulators.
Piecemeal solutions like error-prone age-identification algorithms and measures that can easily be circumvented by VPNs and false IDs are not the answer to protecting children from theft and abuse of their privacy.
Reuters headline on August 14, 2025.
Journalists reporting on problems like Meta’s policies that allowed the company’s AI to engage in sexual and racist conversations with children help to raise adult awareness of the serious risks to kids. Regulatory actions like those of the U.K. and Australia to implement age restrictions for potentially harmful material further heighten public concern. More corporate transparency, which could include measures requiring disclosure of proprietary algorithms, and collaboration among governments to find the best possible solutions, are necessary.
Changing the narrative about “free speech” is also crucial. Unlimited online speech and content are not “free” when they can cause irreparable harm to defenceless kids. Instead, speech and content of that nature should be described as what they are: “irresponsible.” Words matter, and promoting “irresponsible” speech is clearly indefensible when calling the same speech “free” makes it seem constitutional.
The moral and legal responsibility of adults to protect children from online harm should be codified in law, with steep financial penalties for adults and companies crossing the line. Fines against tech giants that intrude on the digital privacy of children should be especially severe, far outweighing the profits they’re currently deriving from the offences.
The responsibilities of adults to children are absolute and non-negotiable. Depriving children of digital privacy is theft and abuse, and should be prosecuted as such.


