
Image: Gerd Altmann, on Pixabay.
By Mariana Meneses
Social media platforms have become some of the most influential information infrastructures in human history, shaping what billions of people see, read, discuss, and ultimately pay attention to. Yet the systems that govern these flows of information remain only partially visible to the public. While companies publish broad descriptions of how their recommendation systems operate, the detailed mechanisms that determine who sees what content, why certain posts are amplified, and how engagement is optimized remain largely inaccessible to independent scrutiny. As evidence of their societal effects accumulates, governments, courts, researchers, and civil society organizations increasingly demand transparency, accountability, and public oversight.
“In 2025, Meta Platforms had a total annual revenue of over 200 billion U.S. dollars, up from 164 billion in 2024. LinkedIn reported its highest annual revenue to date, generating over 17 billion USD, whilst Snapchat reported an annual revenue of 5.9 billion USD.” – Statista
The stakes are amplified by the economic incentives driving these systems. Social media companies generate tens of billions of dollars annually, primarily through advertising revenue that depends on attracting and retaining user attention. In 2025, Facebook and Instagram owner Meta reported more than $200 billion in annual revenue, while Microsoft-owned LinkedIn generated over $17 billion and Snapchat nearly $6 billion. In the first quarter of 2026 alone, Meta’s Family of Apps business segment generated approximately $55.9 billion in revenue, with 98% (about $55 billion) coming from advertising. The algorithms that curate online feeds are therefore not merely technical tools; they are central components of business models designed to maximize engagement in one of the most competitive attention economies ever created.

March 25, 2026 New York Times headline.
This combination of enormous social influence, limited transparency, and powerful commercial incentives helps explain why researchers, regulators, courts, and civil society organizations have increasingly focused on the governance of social media algorithms. As concerns grow over misinformation, political polarization, mental health, privacy, discrimination, and election integrity, a central question has emerged: should private companies alone determine how the information environment for billions of people is structured?
Researchers and civil society are pushing back
In May 2023, in a response to the European Commission’s call for evidence on a delegated regulation governing data access under the Digital Services Act (DSA), the Mozilla Foundation, AlgorithmWatch (a non-profit organization based in Berlin and Zurich), Amnesty International, the Institute for Strategic Dialogue, Avaaz, AI Forensics, and numerous other civil society organizations and researchers argued that public-interest researchers need meaningful access to social media data to investigate systemic risks such as misinformation, threats to election integrity, privacy violations, and other societal harms.
The coalition recommended that platforms be required to provide complete, historically available, and verifiable public data, including metadata and documentation of platform changes. They called for platforms to support multiple forms of access, including APIs, scraping, data donation, and research interfaces. They advocated for assurances that research access is affordable, timely, and sustained over long periods, and that platforms refrain from obstructing independent research through technical restrictions, contractual barriers, or legal threats. The signatories further argued that researchers and journalists inside and outside the European Union should be able to access platform data under the spirit of the EU’s Digital Services Act, emphasizing that transparency and data access are essential for accountability, regulatory oversight, and independent scrutiny of large online platforms.

Image: Gerd Altmann, via Pixabay.
Critics argue that access has often moved in the opposite direction. In his 2024 article “European Regulators Are Right to be Concerned About The State of X’s Transparency,” Brandon Silverman contends that X dismantled much of its research infrastructure by eliminating its free researcher API, laying off research-support teams, and effectively ending thousands of ongoing studies. While commercial partners continued to receive real-time data, Silverman argues that researchers faced limited transparency regarding approval criteria, available datasets, and access conditions, raising concerns that formal transparency obligations could be satisfied without providing meaningful public oversight.
The debate also entails what kind of access should be permitted. In “The Stakes of ‘Publicly Accessible’ Researchers’ Rights to Data under the DSA,” Daphne Keller, Director of Platform Regulation at Stanford Law School’s Program in Law, Science & Technology, argues that the success of the EU’s Digital Services Act depends on interpreting “publicly accessible” data broadly enough to support meaningful independent research on misinformation, content moderation, election integrity, platform governance, and other systemic risks. She argues that the law was designed to remove barriers historically imposed through restrictive terms of service, anti-scraping measures, and legal threats, while balancing privacy and other rights through safeguards governing how data is collected and used rather than by restricting access altogether.
These concerns are increasingly being translated into regulatory practice. According to the European Commission’s 2025 guidance on researcher access under the Digital Services Act, researchers now have unprecedented legal rights to access data from Very Large Online Platforms and Search Engines (VLOPs and VLOSEs) to study risks including misinformation, illegal content, threats to fundamental rights, election integrity, public health, child safety, and other online harms. Independent researchers can access public platform data, while vetted researchers affiliated with research institutions can request access to certain non-public datasets through a formal review process. The Commission has also introduced a data-access framework that includes a dedicated portal, standardized procedures, and platform data catalogues, while investigating companies such as X, Meta, TikTok, and AliExpress over suspected failures to comply with their transparency obligations.
Governments and courts are starting to intervene. Who gets to decide how these systems operate?
As concerns about algorithmic governance have grown, courts are increasingly being asked to decide where platform authority ends and public accountability begins. Cases involving researcher access, user control over feeds, and platform design are beginning to test the legal boundaries of Big Tech power.
According to the Center for Countering Digital Hate (CCDH), a U.S. federal judge dismissed all claims in a 2024 lawsuit brought by X against the nonprofit after it published research on hate speech and misinformation on the platform. X argued that CCDH’s reporting contributed to lost advertising revenue, but the judge concluded that the case was fundamentally about punishing criticism rather than addressing research methods. The ruling was widely interpreted as reinforcing the ability of researchers and civil society organizations to investigate and publish findings about platforms that play a significant role in public discourse.
Questions about user control over algorithmic feeds have also reached the courts. In “Facebook Banned Me for Life Because I Help People Use It Less,” Oxford Internet Institute research associate Louis Barclay, founder of PikTop, the world’s biggest public leaderboard of TikTok videos, recounts how Facebook permanently disabled his accounts and forced him to shut down Unfollow Everything, a browser extension that allowed users to remove their News Feed while retaining access to friends, groups, and pages. Barclay argues that the tool reduced compulsive scrolling, gave users greater control over their experience, and was even adopted by researchers studying the effects of the News Feed on behavior and well-being. His experience later became the basis for a broader legal challenge.
According to an Associated Press report by Barbara Ortutay, a 2024 lawsuit filed against Meta by the Knight First Amendment Institute on behalf of University of Massachusetts professor Ethan Zuckerman sought to establish that users have the legal right to employ external tools that modify or eliminate Facebook’s algorithmic News Feed. Centered on Unfollow Everything 2.0, the lawsuit argued that Section 230 of the U.S. Communications Decency Act protects not only platforms but also developers who create tools enabling users to filter content.
The most consequential legal challenge may concern the engagement-driven design principles underlying modern social media platforms. According to reporting by Rob Nicholls (The Conversation), Lily Jamali (BBC), Dara Kerr (The Guardian), and Bobby Allyn (NPR), the 2026 KGM v. Meta and Google case became a landmark test of whether social media companies can be held legally responsible for harms associated with systems deliberately designed to capture and retain attention.
Inside Landmark Verdict In Social Media Addiction Trial— And What It Means For Future Of Big Tech | Forbes Breaking News
The plaintiff argued that features such as infinite scroll, autoplay, notifications, recommendation algorithms, and beauty filters (augmented reality effects that use AI to alter facial features and skin texture in real-time) were engineered to maximize engagement and contributed to severe mental health harms.
Internal company documents presented at trial reportedly compared platform effects to drugs and gambling and acknowledged concerns about user addiction. A California jury ultimately found Meta and Google liable, awarding US$6 million in damages and concluding that the design of Instagram and YouTube was a substantial factor in the plaintiff’s depression, anxiety, and body-image struggles. Linked to roughly 2,000 similar lawsuits, the verdict was widely described as a potential “Big Tobacco moment” for social media, shifting legal scrutiny from user-generated content to the design of the systems that deliver it and potentially opening new avenues for platform regulation and accountability.
The hard part: oversight without overreach
According to the European Broadcasting Union (EBU), growing reliance on algorithmic platforms, connected devices, and AI systems is giving large technology companies increasing influence over how audiences discover news and audiovisual content. In a 2026 position paper, the organization argues t/hat the European Union should revise the Audiovisual Media Services Directive (AVMSD) to ensure the visibility of public-interest media, reduce regulatory gaps between digital platforms and traditional broadcasters, and address practices such as unfair revenue sharing, ad replacement, and restrictive linking policies. The EBU warns that without stronger safeguards, dominant technology platforms could weaken access to reliable journalism, cultural diversity, and media pluralism, raising broader questions about who controls the flow of information in democratic societies.
Algorithm governance emerges in China.
According to legal scholar Luiza Jarovsky, legal analyst Xia Yu, the International Trade Trust Compliance Network, and reporting by Global Times, China has introduced what may be the world’s most comprehensive regulatory framework for AI systems designed to simulate human-like personalities, relationships, and emotional interactions, including virtual companions, AI partners, emotionally responsive chatbots, and digital assistants. The framework regulates the full lifecycle of these services, from training data and algorithm governance to security assessments, content moderation, data protection, operational safety, and legal liability, while requiring clear disclosure that users are interacting with AI rather than humans.
Reflecting concerns about psychological harm, emotional dependency, addiction, manipulation, and self-harm promotion, the rules prohibit emotional or algorithmic techniques that unduly influence users, require anti-addiction measures such as dependency warnings and reminders after prolonged use, and establish safeguards including mental health protections, easy exit mechanisms, algorithm registration, security assessments, and incident-response programs. They also introduce stronger protections for vulnerable groups, including parental controls, age verification, usage limits, restrictions on emotional-companionship services, and a ban on virtual companion, virtual family-member, and virtual intimate-relationship services for minors. Commentators argue that China is moving toward highly specific governance of these systems, raising a dilemma around how to protect users from manipulation without normalizing excessive state control over digital life.
Latin America could also be moving beyond transparency requirements and toward direct regulation of digital platforms.
According to the Brazilian government and Agência Brasil, Brazil’s Digital Statute for Children and Adolescents (Digital ECA), which took effect in March 2026, establishes a comprehensive online child-safety framework covering social media, games, video platforms, and online marketplaces. The law requires age verification, parental-control tools, victim-support channels, and the rapid removal of content involving sexual exploitation, grooming, violence, bullying, drug use, and self-harm. It also prohibits manipulative design features that encourage compulsive use, strengthens data-protection requirements, expands regulatory oversight, and imposes significant penalties for noncompliance.
The legislation responds to growing concerns about online harms in a country where 92% of children and adolescents use the internet and more than half of surveyed teenagers report experiencing some form of online sexual violence. More broadly, it illustrates a growing willingness among governments to regulate not only online content, but also the design features and incentive structures through which digital platforms influence behavior.
What do we know about how these algorithms work and the risks they pose? Why should we care about algorithmic governance?
In a blog post entitled “Social media algorithms in 2026: How they rank content”, social media strategist Michelle Martin explains that social media algorithms are AI-powered systems that replace chronological feeds by ranking content according to engagement signals, relevance, and user behavior.
Using machine learning, they personalize feeds based on factors such as watch time, likes, comments, shares, previous interactions, interests, location, keywords, hashtags, and content format. Across platforms, these systems generally follow a similar process: selecting eligible content, evaluating ranking signals, predicting its relevance to a specific user, and ordering posts accordingly. AI increasingly drives recommendation, moderation, trend detection, and personalization, shaping how content is surfaced and distributed online.
How Social Media Algorithms Actually Work (And How to Beat Them) | Kallaway
In an article entitled “What are algorithms and how do they make social media more harmful?”, the Center for Countering Digital Hate (CCDH) warns that social media algorithms can amplify harmful material, including misinformation, hate speech, self-harm content, and conspiracy theories, because emotionally charged and controversial posts often generate stronger reactions, and therefore greater visibility.
In “Ranking for engagement: How social media algorithms fuel misinformation and polarization,” published in the Journal of Public Economics in 2026, Fabrizio Germano, from Pompeu Fabra University, and co-authors examine what happens when social media feeds are optimized for engagement. Their theoretical model shows that politically extreme users tend to react more intensely than moderates, giving engagement-based algorithms a structural incentive to amplify more polarizing and potentially misleading content. When recommendation systems are personalized, this dynamic becomes even stronger, because users are not only exposed to highly engaging content in general, but to the kinds of content most likely to trigger individual reactions. The paper shows that Facebook’s 2018 “Meaningful Social Interactions” update, which gave greater weight to engagement metrics in content ranking, contributed to higher levels of ideological extremism and affective polarization.
The effects of these systems appear to reach far beyond political attitudes alone.
Researchers argue that algorithmic curation affects how people encounter information, form identities, and participate in public life.
According to Mukhtar Ahmmad, from Government College University, Pakistan, and co-authors in the 2025 Societiesreview “Trap of Social Media Algorithms: A Systematic Review of Research on Filter Bubbles, Echo Chambers, and Their Impact on Youth,” evidence from 30 studies suggests that social media algorithms amplify ideological homogeneity by prioritizing content aligned with users’ existing preferences, contributing to filter bubbles and echo chambers that limit exposure to diverse viewpoints. Across platforms including Facebook, YouTube, X, Instagram, TikTok, and Weibo, recommender systems were found to reinforce confirmation bias, intensify polarization, and sometimes steer users toward sensationalist, extremist, or misleading content.
The review also finds that many young people recognize these dynamics and actively try to diversify their information environments, although such efforts are often constrained by opaque platform designs and uneven levels of digital literacy. The authors therefore argue for greater algorithmic transparency, stronger media literacy education, and youth-centered approaches to platform governance.

Image: Gerd Altmann, via Pixabay.
Some researchers argue that feeds are not merely selecting content but implicitly promoting certain values.
In “Value Alignment of Social Media Ranking Algorithms,” Farnaz Jahanbakhsh, from the University of Michigan, and co-authors show that social media feeds are not value-neutral because engagement-based ranking tends to amplify content associated with short-term, individual-focused values such as pleasure, novelty, and stimulation, even when platforms do not explicitly choose a value system.
To explore alternatives, the authors developed a system that allows users to prioritize the values they wish to see either more or less in their feeds. In two controlled experiments, users could distinguish value-aligned feeds from engagement-ranked feeds above chance. The study also found that engagement-ranked feeds emphasized personal values more strongly than social values, while value-aligned feeds increased content related to self-transcendence and openness to change. Jahanbakhsh and co-authors argue that social media ranking systems could make their underlying values explicit and adjustable rather than leaving them as hidden byproducts of engagement optimization.
Questions about engagement optimization have also been raised in relation to mental health.
According to Debasmita De, from the Vanderbilt University Medical Center, and co-authors in the review article “Social Media Algorithms and Teen Addiction: Neurophysiological Impact and Ethical Considerations,” social media platforms use AI-driven recommendation systems that exploit the brain’s reward circuitry by continuously delivering personalized content designed to maximize engagement and screen time.
The authors argue that repeated exposure to algorithmically optimized feeds can reinforce dopamine-mediated reward pathways in ways analogous to behavioral addictions, particularly among adolescents, whose heightened sensitivity to rewards makes them especially vulnerable. The review links prolonged social media use to structural and functional changes in brain regions involved in reward processing, emotional regulation, impulse control, decision-making, memory, and attention, including the prefrontal cortex, amygdala, basal ganglia, and anterior cingulate cortex. It further highlights evidence associating social media use with anxiety, depression, impaired sleep, reduced inhibitory control, and risk-taking behaviors, while raising ethical concerns about data collection, algorithmic manipulation, inadequate informed consent, and business models that prioritize engagement and advertising revenue over adolescent well-being.
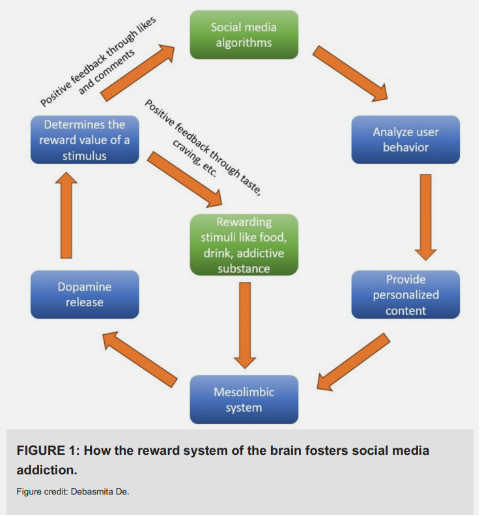
Credit: Debasmita De et al (2025).
At the same time, the data collection required to power personalization systems may create additional risks.
In “Double-Edged Sword of Social Media Algorithms: Assessing the Risks to University Cybersecurity and Student Data Privacy,” Weishu Ye and Zhi Li, from the NingboTech University, China, argue social media algorithms can increase privacy and cybersecurity risks by encouraging users to share personal information that is then aggregated across platforms to build detailed digital profiles. The authors found that students who disclosed more information online were substantially more likely to experience security incidents such as phishing attempts, abnormal account logins, and privacy breaches.
Moreover, extensive data collection through third-party tracking software embedded in social media apps increased the risk of cross-platform identification and profiling, while periods of heightened stress, such as exam weeks, were associated with sharp increases in risky self-disclosure. The study concludes that algorithm-driven recommendation systems, combined with large-scale data collection and personalization, can transform everyday online activity into a source of cybersecurity vulnerabilities, particularly for young users with limited privacy awareness.
Despite their growing influence over public discourse, many recommendation systems remain largely opaque. Researchers argue that if algorithms shape polarization, information flows, mental health, and the visibility of knowledge, independent scrutiny is necessary to understand and evaluate their societal impacts.
Yet the push for accountability also has a boundary problem. If platforms can exercise too much unchecked power, could governments also demand excessive access?
According to Reuters reporter Stephen Nellis, Apple, Google, and Meta urged Canadian lawmakers in 2026 to amend Bill C-22, an online safety proposal intended to assist criminal investigations, to include explicit protections for encryption and judicial oversight. Although the bill does not directly require companies to weaken encryption, the firms argued that it could enable secret government orders compelling them to create undisclosed access mechanisms, or “backdoors,” into devices and services. They warned that such powers could undermine end-to-end encryption, which prevents even technology companies from accessing users’ communications without the appropriate encryption keys.
While the debate does not concern recommendation algorithms directly, it illustrates a broader challenge of digital governance: how to make powerful technologies more accountable without weakening the privacy, security, and civil-liberty protections designed to safeguard users.
Taken together, the evidence reviewed here suggests that social media algorithms are far more than neutral recommendation tools. Research links engagement-driven ranking systems to polarization, misinformation, filter bubbles, addictive use patterns, privacy and cybersecurity risks, and unequal visibility within knowledge communities. At the same time, studies suggest that algorithmic systems embed value judgments, shape what information people encounter, and influence how public attention is allocated. These concerns have fueled growing demands for transparency, independent research access, regulatory oversight, and legal accountability, prompting interventions from researchers, civil society organizations, courts, and governments around the world.
Decisions about what information is amplified, what content remains visible, which risks deserve mitigation, how users are protected, and what trade-offs are acceptable are increasingly being embedded in algorithmic systems that operate at planetary scale. Societies must now decide who governs these systems, according to which values, and with what forms of accountability.
Craving more information? Check out these recommended TQR articles:
- Thinking in the Age of Machines: Global IQ Decline and the Rise of AI-Assisted Thinking
- Digital Sovereignty Movement Grows as Global Infrastructure Concentrates Under Few Companies
- Nations Adopt Digital IDs for Citizens, While Critics Highlight Privacy Issues
- Cleaning the Mirror: Increasing Concerns Over Data Quality, Distortion, and Decision-Making
Enjoyed this? Help us improve.
Have we made any errors?
Spotted an error or want to contribute your expertise? We’d love to hear from you — reach us at info@thequantumrecord.com. The Quantum Record exists to bring researchers and curious minds together around science and technology that matters.



