
Illustration of the opportunities and challenges of DNA editing from the United States Government Accountability Office.
By James Myers
This article is part of The Quantum Record’s ongoing series on Quantum Ethics, with six issues introduced in our May 2024 feature Quantum Ethics: There’s No Time Like the Present to Plan for the Human Future With Quantum Technology.
There remains so much to be discovered about the operation of human DNA.
Longstanding and well-respected rules have existed to prevent DNA experimentation with humans at any stage before and after birth. At the same time there exists, in CRISPR technology, the power to edit DNA – including human DNA – with great precision.
We will outline some of the powers that quantum computing could lend to the gene editing process, and ask what that power will be used for and how its risks will be controlled. Although the questions have not yet been the subject of broad discussion, a recent case of gene editing abuse gives cause for concern.
We’ll look first at what happened, and then at what might happen.
In 2018, one man took the potential of a human embryo’s genome into his hands.
Following a three-year prison sentence for practising medicine without a licence in his uncontrolled and unauthorized gene editing of three human embryos in 2018, scientist He Jiankui was released in 2022 and is now back at work editing human genes.
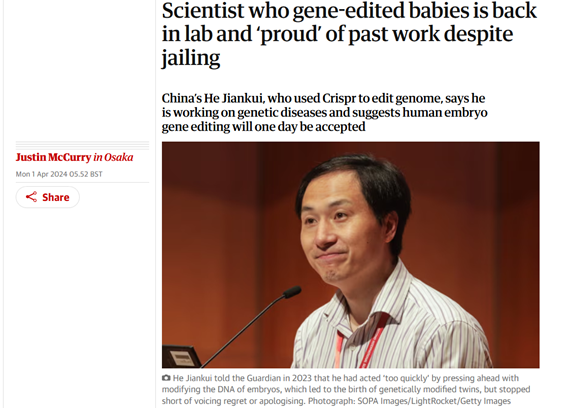
April 1, 2024 headline in The Guardian
Jiankui’s crime, tried by a Chinese court in 2019, was a serious violation of national and international legal and scientific standards against experimentation with the human genome.
While nearly the entirety of the human genome (but not quite all, as we reported in our December 2022 article Discovering the Human Code) has now been sequenced and the science of genetics has rapidly advanced, the technology is so relatively new that little is known about its long-term consequences that we might think very improbable today.

A male human embryo 7 weeks after conception. Image: Wikipedia .
Far greater scientific evidence is required to establish our skill at DNA editing, especially our skill – or lack of it – in modifying our own human genes. There is insufficient data to establish consistently verifiable results, which is a keystone requirement of the scientific method.
Genetics, for example, has no way of predicting with near-certainty whether a healthy five-year-old girl today will wind up with cancer fifty-five years later, entering her senior years. Genetics involves knowledge of DNA’s geometric structure and a huge array of variables in its operation, so such a gene-predicting feat would include overcoming the probability measurement hurdles of the so-far ironclad Heisenberg’s Uncertainty Principle and Gödel’s Incompleteness Theorems.
As a result, there are well-established and long-respected rules against genetic experimenting on such a precious thing to all of us as the human body is.
The same principles underlie the extreme precautions that we take against exporting microbes from Earth that would be alien on an extraterrestrial body, for example when probes are manufactured to explore the surface of places like the Moon or Mars.
The potential risks of manipulating the human genome are considered so serious that in 1997 the United Nations adopted a Universal Declaration on the Human Genome and Human Rights.
Article 5 of the Declaration requires “rigorous and prior assessment of the potential risks and benefits” before any research, diagnosis, or treatment of an individual’s genome within the constraints of national laws, together with “free and informed consent of the person concerned,” and a provision that “protocols shall, in addition, be submitted for prior review in accordance with relevant national and international research standards or guidelines.”
The laws of many nations restricting and controlling human genetic experimentation reflect the principles set out by 37 years ago by the United Nations. In Canada, for example, the Assisted Human Reproduction Act of 2004 makes editing the human genome in any way that can be inherited punishable by up to ten years in prison. The law includes a range of other crimes, including human cloning and the making of embryos for the sole purpose of experimentation.

Part of the United Nations’ November 11, 1997 Universal Declaration on the Human Genome and Human Rights.
All’s well that ends well, or has time yet to tell how probabilities will unfold in the future?
Fortunately, Jiankui’s edited babies are now, as he told Japan’s Mianichi Shimbun news outlet, “perfectly healthy and have no problems with their growth.” Jiankui reports that his analyses of the children’s entire gene sequences “show that there were no modifications to the genes other than for the medical objective, providing evidence that genome editing was safe.” In spite of his jail sentence, he stated, “I’m proud to have helped families who wanted healthy children.”
The edited babies are now five years old. Jiankui’s experiment, conducted on eight couples in which the fathers had HIV, was intended to ensure the babies would be born HIV-free by disabling genes targeted by the virus. Of his international rule-breaking experiment, Jiankui stated, “I regret that it was too hasty.”

Image: UK National Health Service, Three Things We Learnt From the Discovery of DNA’s Structure
Now free, Jianqui’s goal is to create treatments for rare diseases like Duchenne muscular dystropy and Alzheimer’s transmitted in the DNA of certain families.
After reportedly creating three laboratories since his release from prison, he has pledged, “We will use discarded human embryos and comply with both domestic and international rules.”
Jianqui is not alone in his desire to alter DNA to relieve human suffering from illness. Manipulating genetics to treat disease has the support of many people, but a 2022 Pew Research Center survey indicates that opinions are evenly and sharply divided on the question, with more than one third of Americans unsure of the issues and what should be done about them.

In 2022, the Pew Research Center asked Americans for their views of gene editing to reduce disease risk. Opinions were closely divided.
Only time will tell whether Jiankui and other scientists with access to present and future powerful gene editing technology will comply with existing rules and ethical guidelines.
Haste, as Jiankui claimed, is only one possible motivation for violation. The potential monetary rewards for successful designer babies could also be a significant draw for more unauthorized experimentation.
Gene editing technology is so consequential that it was the basis of the 2020 Nobel Prize in Chemistry.
TQR’s September 2022 article, CRISPR Technology: Editing the Genetic Code, From Plants to Humans, explained the advanced methods now used for gene editing. Thanks to the work of 2020 Nobel Prize-winners Drs. Emmanuelle Charpentier and Jennifer Doudna, as well as others, geneticists can edit specific parts of a genome by removing, adding, or changing sections of the DNA sequence.
There are even customized enzymes that, when used in the CRISPR system, do not change the DNA sequence at all, but instead activate or silence specific genes.
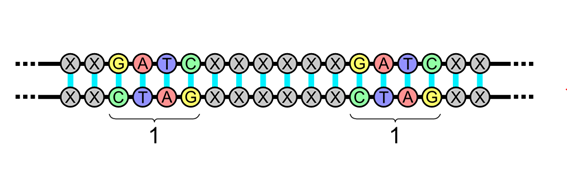
Illustration of a palindromic sequence in a double-stranded DNA molecule, in which the sequential operation of one strand is identical to the sequence in the opposite direction on the complementary strand. For more see CRISPR Technology: Editing the Genetic Code, From Plants to Humans
The technology’s development was based on the way that a virus inserts itself into the DNA of a bacterium. The last three letters of the CRISPR acronym refer to the short, palindromic, and repeating DNA sequences of a virus within its host bacterium.
The illustration above, of two strands connected at every point, demonstrates how a repeating matrix can develop in the connections of multiple layers of DNA strands. Our DNA is geometric, consisting of a hexagonal double helix of joined pairs of molecules, and it’s within that geometry that the molecules of our DNA synchronize their operations in complex matrix structures.
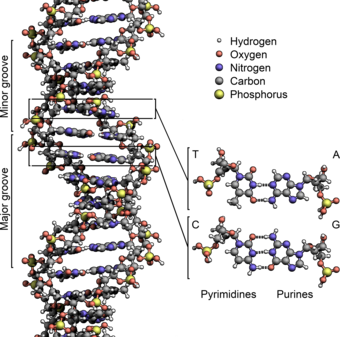
The structure of the DNA double helix (type B-DNA). The atoms in the structure are colour-coded by element and the detailed structures of two base pairs A-T and C-G are shown in the bottom right. Image by Zephyris, in Wikipedia .
The speed of quantum computers makes them especially good for finding and copying combinations like those in the DNA double helix.
DNA is the operating instruction set for everything that our bodies do, and sometimes don’t do, for us. In DNA, the instruction set always consists of an adenine (A) molecule paired with a thymine (T) molecule. The A-T molecular set always joins with a pairing of cytosine (C) and guanine (G) molecules, with the result being a mixture of four molecules ATCG but in any and all possible orders and combinations that four can produce when paired in two sets of two each.
The combinatorial probabilities of the paired connections in DNA can be expressed mathematically, and mathematics can be especially helpful in describing and copying sequences. When Francis Crick and James Watson, who co-discovered the helical structure of DNA, published their famous 1953 paper, Molecular Structure of Nucleic Acids, they wrote, “It has not escaped our notice that the specific pairing we have postulated immediately suggests a possible copying mechanism for the genetic material.”

Part of a chart from Symmetry and Simplicity Spontaneously Emerge from the Algorithmic Nature of Evolution, demonstrating the high frequency of symmetry in complex protein structures called polyominoes based on a study of 34,287 protein complexes extracted from the Protein Data Bank.
Copying a three-dimensional structure that’s always in motion, like DNA with its variable sequences of four molecules, is a challenging task for the most capable supercomputers in use today. Each strand of the structure contains many possible combinations, but when paired with another strand the combined combinations are far greater. Then, when two paired strands are put into constant motion in opposite directions, there is an even more vast number of probabilities in their combinations.
Quantum algorithms can be designed to identify symmetries, or equivalences, within a large range of probabilities.
The evolution of a structure like DNA operates algorithmically, meaning that it progresses according to sequences of instructions, which makes it computable. The ease of computability is significantly enhanced by the presence of symmetries, which reduce the information burden.
A 2022 research article by University of Oxford physicist Dr. Ard Louis and co-authors, entitled Symmetry and Simplicity Spontaneously Emerge from the Algorithmic Nature of Evolution, explains findings of a significant prevalence of mathematical symmetry in natural structures, like DNA.
The article states that “Since symmetric structures need less information to encode, they are much more likely to appear as potential variation.” The article attributes the high degree of symmetry in evolution to repetition in subunits of biological structures, resulting in highly compressible data and less constraints on the genetic material.
Mutations of symmetric structures will produce further symmetry, implying that “a strong bias toward symmetry may emerge even without natural selection for symmetry.”
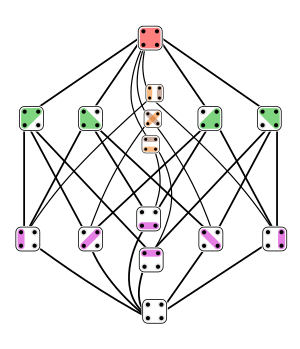
Symmetries are evident in the partition of a set (in two dimensions of length and width) of four elements (in green), which is further subdivided into a set of 6 (in purple) to produce 15 possible combinations. Quantum computers will be especially effective in determining combinations based on symmetries. Image of a lattice in a Hasse diagram from Wikipedia .
The speed at which quantum computers can examine combinations and equivalences has already made the machines powerful partners in the search for new drugs to battle disease.
The quantum information bits, or qubits, in quantum computers can simultaneously measure all possible values of a complex function, identifying the maximum and minimum limits of probability within the mathematics and three-dimensional geometry of the function.
The qubits can do this because they are in a state of superposition, operating in opposite “on” and “off” states at the same time. Superposition provides an incredible speed advantage over regular computer bits, which require time to switch between states because they can be in only one of two states at any time.
There is growing interest in quantum computing’s potential for drug development.
Even without fully functional quantum computers yet, existing computational power is making impressive advances in drug development. There is, however, clearly an interest in expanding the computing successes by adding the speed and accuracy boosts of quantum computing to drive even more transformative drug development.
Clear evidence of the crucial stake the pharmaceutical industry is placing in the future of quantum computing is the number of patents applied for or issued that contain a reference to the emerging technology. The following chart compares the quantum-based patent numbers of a several major top pharmaceutical companies over a five-year period.

The chart demonstrates the growing pharmaceutical industry interest and investment in patents involving quantum computing technology. Credit: Quantum medicine: how quantum computers could change drug development
Using existing technology, this month Google’s DeepMind division introduced its new product, AlphaProteo, and published an outline of its machine-learning algorithms which don’t require quantum computing’s unique capabilities.
AlphaProteo is the company’s first AI system for designing new mechanisms to bind proteins to molecules. Every biological process in the body is operated by protein binding, which regulates the function of all of our cells.

DeepMind’s AlphaFold technology preceded AlphaProteo. The image from the AlphaFold website invites users to “View over 200 million protein structure predictions to support your research.” Image: Google DeepMind
The company expects AlphaProteo will provide, as its announcement states, “building blocks for biological and health research. This technology has the potential to accelerate our understanding of biological processes, and aid the discovery of new drugs, the development of biosensors and more.”
AlphaProteo is the first technology capable of generating new binders for the specific protein associated with cancer and complications from diabetes, in addition to an array of other any other binders the user specifies.
AlphaProteo followed the 2018 introduction of AlphaFold, Google’s path-breaking software to predict the folding of proteins in geometric patterns that determine their function. After two upgrades since 2018, AlphaFold is an application the company says is now being used by two million researchers in 190 countries. As the company explains, AlphaFold has “already given us tremendous insight into how proteins interact with each other to perform their functions, but these tools cannot create new proteins to directly manipulate those interactions.”
The February 2023 Clinical Trials Arena article Quantum medicine: how quantum computers could change drug development quotes Maximillian Zinner, then a quantum computing researcher at Witten/Herdecke University, Germany, as stating that in 10–15 years, “quantum computers could achieve the ‘holy grail’ of drug development—testing and developing new medications in silico, meaning through computer modelling.”
Zinner stated, “In the end, creating new molecules from scratch is just a very complex optimization problem.”

Illustration of quantum circuitry manipulating opposite points, coloured blue and red, to produce DNA (the helical spirals) from University College London.
Even in its infancy, quantum technology is already leading in resolving the problems of optimization.

Texas A&M Professor James Cai and Ph.D. student Cristhian Roman Vicharra. Image: Texas A&M University.
In February 2024, Imperial College London announced that its researchers, in collaboration with Zhejiang Lab and the University of Science and Technology of China, successfully developed a quantum processor and applied it to two crucial drug design methods: molecular docking and RNA folding prediction.
“This accomplishment marks a significant step toward employing quantum computing to solve practical problems,” the university stated.
In November 2023, Texas A&M University reported researchers had used a quantum computer to map gene regulatory networks (GRNs), which provide information about how genes can cause each other to activate or deactivate.
Knowledge of gene sequences and their effects on each other is crucial to understanding potentially harmful, as well as possibly beneficial, genetic processes.
“The GRN is like a map that tells us how genes affect each other,” A&M Professor Dr. James Cai said. “For example, if one gene switches on or off, then it may change another gene that could change three, or five, or 20 more genes down the line. Because our quantum computing GRNs are constructed in ways that allow us to capture more complex relationships between genes than traditional computing, we found some links between genes that people hadn’t known about previously.”
DNA sequencing technology to detect the order of A-T and C-G “nucleotide” molecules in a segment of DNA is critical to advances in personalized medicine and disease diagnosis. However, even today’s fastest computers require sometimes days to read a complete sequence accurately, since even one error in the ordering of millions of molecular pairs in extremely long DNA chains could render the output useless.
In August 2023, scientists at Osaka University’s Institute of Scientific and Industrial Research used a quantum computer for a significant increase in the speed and accuracy of identifying individual molecules.
“Using a quantum circuit, we show how to detect a nucleotide from only the measurement data of a single molecule,” explains Masateru Taniguchi, lead author of the study. “This is the first time a quantum computer has been connected to measurement data for a single molecule, and demonstrates the feasibility of using quantum computers in genome analysis.”
Pangenomics is an emerging frontier of genetic information that quantum computing can help to unlock.

Software-produced panegenomic analysis of the Streptococcus agalacitiae species, in which each circle represents a separate genome and the radius of each circle represents the extent of the gene family. Image: Wikipedia .
The University of Cambridge, the Wellcome Sanger Institute, and the European Molecular Biology Laboratory’s European Bioinformatics Institute have combined efforts in the use of quantum computing to explore differences in DNA between individuals.
The project has received $3.5 million in funding to develop new algorithms which will be tested on simulated quantum hardware using supercomputers. The researchers think the algorithms could lead to significant breakthroughs in personalized medicine, and could also be applied to pangenomes of viruses and bacteria to improve the tracking and management of disease outbreaks.
A human’s DNA code consists of 6.4 billion letters and while less than 1% of them can differ from person to person, understanding the consequences of such differences among large groups of people in what is called “pangenomics” can lead to important new discoveries about DNA’s operation.
In producing an understanding of the common elements in DNA’s operation within an entire species of biological organisms, like humans, the emerging science could lead to a potential for engineering the characteristics of the species.
Pangenomics requires understanding the overlaps as well as differences among the DNA of many individuals, a task for which the speed and accuracy of quantum computers is well suited.
However, as David Yuan from the European Bioinformatics Institute stated in an April 2024 press release, “On the one hand, we’re starting from scratch because we don’t even know yet how to represent a pangenome in a quantum computing environment. If you compare it to the first moon landings, this project is the equivalent of designing a rocket and training the astronauts. On the other hand, we’ve got solid foundations, building on decades of systematically annotated genomic data generated by researchers worldwide.”

The Seven Bridges of Konigsburg, Germany, was a topoligical, or graphing, problem solved by famed mathematician Leonhard Euler who determined the problem had no solution. The city of Konigsburg encompasses opposite shores of a river and inclues two islands. There are a total of 7 bridges connecting both sides of the city and the islands, and the question was to devise a walk through the city that would cross each of those bridges once and only once.
While the genome of one human can be represented in a linear graph, pangenomic data of many humans can be represented and analyzed as a network, called a sequence graph, which depicts the shared structure of genetic relationships between many genomes.
As the research group states, “Comparing subsequent individual genomes to the pangenome then involves mapping a route for their sequences through the graph. In this new project, the team aims to develop quantum computing approaches with the potential to speed up both the key processes of mapping data to graph nodes, and finding good routes through the graph.”
How will quantum algorithms be applied to human genetics?
Quantum’s potential to advance human health is clearly demonstrated by the investments that major pharmaceutical companies are making in the emerging technology.
It’s not unreasonable to expect that the speed and accuracy of the quantum computer, particularly in assessing the probabilities of complex matrix structures like DNA and proteins that operate our bodies, will provide a significant boost to the already impressive achievements of pre-quantum technology like Google’s AlphaFold and AlphaProteo. Now that scientists have begun work to develop quantum computing algorithms capable of determining pangenomic characteristics between many individuals, it may be only a matter of a short time before the hardware and software of quantum computing will amplify the human health successes of existing technology.

Quantum computing is expected to advance pangenomics, in which genes that are common to both the core and shell of each genome within the same family are identified as the species’ genomic core. Changes to the core would alter the future of the entire structure of individual and combined genes. Image: Wikipedia
At the same time that there is now such great potential in technology, there are some people — scientists and others – who are motivated to act either without appropriate caution or with an intention to violate national and international laws that are based on both logic and ethics.
Is there any guarantee that He Jianqui’s 2018 violation of global rules against human genetic experimentation will not happen again, once or more than once?
Should we be concerned with the potential power of the quantum computer over our own human genetics?

The probabilities of rolling several numbers with two dice is represented, on the vertical axis, as fractions and the equivalent (rounded) decimals. Image: Wikipedia
How can we prevent the possibility that even one individual violating logic and abusing the technology could produce disastrous outcomes far into the future after edited genes are passed from generation to generation, each time with mutations that are impossible to predict in the present?
Anything in the quantum realm is a measure of probability. The answer to the question of how concerned we should be will perhaps depend on how well we understand the probability that motivations – economic or otherwise – will or won’t lead people to abuse technology.
History shows that some long-shot bets on technology don’t turn out as well as intended. In 1957, the drug thalidomide was introduced and marketed to ease pregnant mothers’ morning sickness, but it turned out to cause major birth defects suffered by their newborns for entire lifetimes.
Do we want anyone to hold the power of human genetics in their hands?
Is this something we want to gamble on, even if the odds of anything bad happening in the future seem faint with what we know today? It’s worth a discussion, isn’t it?


