A prototype of IBM’s Watson, an early version of a natural language processing computer. In 2011, the system occupied the space of a large bedroom and famously outcompeted Ken Jennings and Brad Rutter in the game show “Jeopardy!” to win a $1 million prize. The system employed 16 terabytes of random access memory using 90 servers. Image by Clockready, on Wikipedia.
By James Myers
Since generative AI burst into public consciousness in November 2022 with OpenAI’s release of ChatGPT, the pace of change and expansion of computational requirements has continued to accelerate – and so have the burdens and demands on computer memory.
The first widely-based public version of ChatGPT, the large language model chatbot that OpenAI introduced two years ago, was trained on 175 billion different parameters. Each parameter, or data configuration, resides in computer memory that must be available for any of the millions of queries the system receives daily.
While OpenAI hasn’t disclosed the number of parameters used in its latest version, GPT-4o, the enhancements over the past two years required many more parameters – some estimate as many as 1.8 trillion.
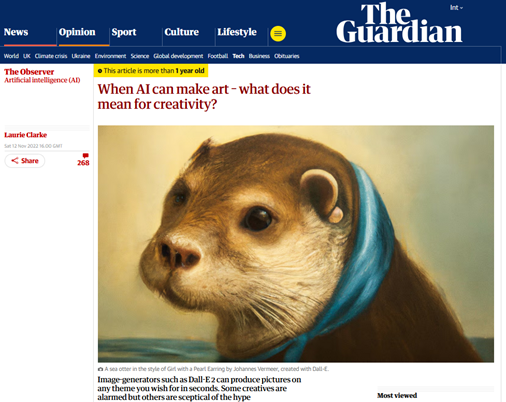
November 12, 2022, headline in The Guardian, when generative AI first drew widespread public attention. The headline question continues to apply two years later. The image in The Guardian’s story was generated by OpenAI’s Dall-E when it was prompted to create “A sea otter in the style of Girl with a Pearl Earring by Johannes Vermeer.” Generated images like this require massive processing capacity.
Google’s chatbot, Gemini, is estimated to use a similar number of parameters or possibly many times more. Both Google and OpenAI provide their chatbots in as many as fifty languages, requiring even greater processing power.
At the same time that generative AI erupted, so did the need for hardware and memory with far greater capacity to support data-intensive image processing and parameter-searching that ChatGPT and other latest-generation applications require. Memory-hungry, high-use applications operate on hardware that is increasingly reliant on memory chips designed by one company, Nvidia.
Nvidia was already known for designing high-capacity computer chips for systems running gaming applications requiring a large volume of data without a loss of processing speed. Over the past two years, Nvidia-designed chips have proven effective for the intensive memory access requirements of large language models like ChatGPT and Gemini, as well as the graphics demands of generative AI applications like OpenAI’s DALL-E.
At the end of November 2022, when ChatGPT first captured global attention, you could buy an Nvidia share for $16.88. At the end of September 2024, nearly two years later, the same Nvidia share would have cost you $124.92. The 13-fold increase in Nvidia’s share price in under two years is due to the skyrocketing demand for its graphic processing units, and over that period, the value of all publicly traded Nvidia shares has skyrocketed to more than $3 trillion. Nvidia’s profits have surged as well: In the first six months of 2024, the company reported a net income of $31.5 billion, which was nearly three times the $8.2 billion profit it made during the first half of 2023.

Headquarters of the $3 trillion company, Nvidia, in Santa Clara, California. Image by Coolcaesar, CC BY-SA 4, on Wikipedia
The introductory version of ChatGPT released in November 2022 is estimated to have required 30,000 Nvidia chips, each costing between $10,000-$15,000 and requiring, according to one report, 500 millilitres of water (equivalent to a 16-ounce water bottle) to cool for every 5 to 50 queries made by a user.
The need for memory is seemingly endless, and the quest for enhanced computing memory is producing some promising candidates.
One study, published in Nature Reviews Electrical Engineering at the beginning of this year, compares four potential upgrades for the rapid-access memory now used in computers.
Computer memory comes in many different types. The memory that is most obvious to everyday computer users is the type that resides on a computer’s hard drive, where data bits are permanently stored whether the machine is turned on or off.
Nvidia released its latest, most powerful chip, called Blackwell, at its 2024 developers’ conference.
A computer requires time to access permanent memory, so to speed up memory-intensive applications when the computer is turned on, key bits of data are temporarily held in SRAM or DRAM memory. SRAM memory retains information for as long as electricity is supplied to its circuits, while DRAM memory typically lasts only seconds before it requires refreshing. SRAM is, however, more expensive and requires more power to maintain, which generates more heat.
One upgraded memory candidate identified by researchers at the Georgia Institute of Technology, led by Anni Lu, Junmo Lee, and Tae-Hyeon Kim, is a DRAM that uses a different material for longer memory retention and doesn’t require a capacitor to store electricity. Another potential option is ferroelectric random-access memory that uses specific metals to switch states with less power, along with magnetic memories that store data bits in specific magnetic alignments.
The two other candidates consist of a multi-dimensional memory that stores data bits in layers and a specific type of SRAM called a leading-edge node that is more effective for cloud-based memory storage. The researchers conclude that more testing of these potential options on silicon-based chips is required and that further improvements are required as physical hardware increasingly moves to virtual cloud-based hardware.
The goal of creating “Turing-complete” computers could require a different memory architecture for large language models.
A computing process is said to be Turing-complete, or ‘computationally universal,’ if it is capable of simulating any algorithm. A Turing-complete process could, therefore, operate any process computable on a hypothetical Turing machine named after Alan Turing. Turing was the brilliant mathematician and computer scientist who provided a massive boost to the Allied victory in World War II against Hitler’s Nazi butchers by helping to decipher their Enigma Code (see TQR’s The Genius of Alan Turing, and the Technology that Cracked the Nazi Enigma Code).

Random access memory (RAM) in computers consists of interchangeable arrays of chips like these. Image: Wikipedia.
In our June 2023 article Beyond the Binary: Can Machines Achieve Conscious Understanding, The Quantum Record described a Turing machine as one that prints an infinite number of outputs on a never-ending tape according to its programmed instructions. The imagined machine can “solve problems and make decisions by transforming the combinations of symbols initially on the tape and adding its own.”
The hypothesized universal Turing-complete machine would operate not only with the specific instructions provided to it but could simulate and operate with the instructions provided to any other Turing machine. Large language models like ChatGPT and Gemini aren’t able to simulate other programs but instead are programmed specifically to decipher the queries of users and assemble the most relevant data in response using a process that requires a vast amount of data.
The “PT” in ChatGPT is the acronym for “Pre-trained Transformer,” a term that Google coined for an algorithm that receives a string of words but doesn’t evaluate each one by itself. Instead, the transformer evaluates the string’s connections to the words it has already been fed during its machine learning, and its algorithm “transforms” the whole input into a new output of word strings.
In an August 2024 article entitled Why the T in ChatGPT is AI’s biggest breakthrough – and greatest risk, a research scientist at Google’s DeepMind division, Razvan Pascanu, explained to New Scientist Magazine that Turing complete computers are important for the future development of computers that are reliable and capable as we want them to be.

Machines require time to “learn” from human data. The machine learning of the latest version of ChatGPT is now one year out of date. AI-generated image by Entre-Humos on Pixabay.
As more people begin to rely on chatbots like ChatGPT and Gemini for their web searches, a critical limitation that reduces the reliability of the outputs is the missing time in their training data. For example, the latest version of ChatGPT was “trained” on data available up to October 2023. ChatGPT’s algorithms have no record, and therefore no memory, of the information and knowledge accumulated by the world’s 7.8 billion humans over the past year.
Some ChatGPT outputs, particularly those sensitive to recent developments in science, could be especially unreliable.
The memory of ChatGPT, Gemini, and other pre-trained transformers is not only time-deficient, but its structure requires an immense processing capacity. In the New Scientist article, writer Alex Wilkins states, “Transformers must also repeatedly look back at data they have already seen. Processing and generating long text sequences can require enormous computational resources as the AI scans back and forth.” As Yoon Kim at the Massachusetts Institute of Technology explained to Wilkins, “This isn’t as much of a problem when working with short emails or simple questions, but it makes transformers ill-suited for working with much longer text sequences, like books or large data sets.”
The article concludes that “Transformers are just fundamentally inefficient and are ill-equipped for these types of applications.”
The power of the human mind shouldn’t be overlooked in the design of computer memory.
This July, a reader asked New Scientist Magazine, “If someone could have their life extended with no limit, would their brain eventually run out of storage space?” The answer given was, perhaps surprisingly, no. The more than 86 billion neurons that transfer electrical signals in the human brain appear to be capable of operating without a storage space limit.
The editors observed, “If you think about it, during your lifetime, from birth to, say, 80, the amount of day-to-day information that is fed to your brain is simply (and literally) mind-boggling. If the brain were a simple computer, it would have physically run out of storage space when you were a few years old. Therefore, your brain must function in a way where all the information that is being fed into it is constantly deleted after a short period. To remember something, you have to repeatedly feed that same information (think of revising for exams) to your brain.”
Depiction of the network of neurons in the human brain by ColiN00B on Pixabay.
Being limited by the energy that our bodies can produce, the memory function of human brains operates very differently from energy-hungry and hardware-dominated memories that feed large language models and other data-intensive computing functions. While there remains much to be learned about the operation of human memory, studies have shown that it works with several processes in parallel and uses hierarchies that reassemble past information rather than storing exact copies of all data and sequences in the brain.
As an article by Harvard University’s Derek Bok Center for Teaching and Learning explains, there are several theories for how human memory operates. Citing current research in cognitive science, the article states that human memory “operates according to a ‘dual-process,’ where more unconscious, more routine thought processes (known as ‘System 1’) interact with more conscious, more problem-based thought processes (known as ‘System 2’). At each of these two levels, in turn, there are the processes through which we ‘get information in’ (encoding), how we hold on to it (storage), and how we ‘get it back out’ (retrieval or recall).”
Although no human brain could retain the impressive volume of data that ChatGPT can handle, the individually creative and collective feats that the brains of 7.8 billion humans can perform are far more remarkable than the machine’s memory.
Could origami provide a more efficient model for computer function and memory?
Physicist Michael Assis applies the properties of statistical mechanics, which typically explores the behaviour that emerges from the networks of interactions of many particles, such as gas or water molecules, to an origami structure. The folds in the origami take the place of the networks among particles, and in a paper posted on arXiv this March, Assis proposes an origami universal Turing machine design.
In this Quanta Magazine YouTube video, Michael Assis explains the potential usefulness of origami and the relationships of its defects for statistical mechanics. The Quanta Magazine article The Atomic Theory of Origami describes the relationship of origami to statistical mechanics in further detail.
The idea of computation in a folded structure may not seem so far-fetched, considering the vast number of folds that exist in the human brain and that our neurons operate in multiple layers in different areas of the brain. For example, our neocortex comprises six neuronal layers, while our allocortex has three or four.
In his paper, Assis asks “whether origami possesses enough complexity to be able to perform arbitrarily complex calculations, that is, whether a Universal Turing Machine could be constructed from paper using origami.” The operation of such a machine, he states, would be facilitated by the use of a computing language like P” which uses binary symbols and avoids “Go To” statements that would require jumps to arbitrary locations in the origami structure.
As Assis explained to New Scientist this June, “You have two folds that have to come in, but then they will only fold if the third one is folded in one way or the other, and that is essentially doing a very, very simple computation. And then the trick is combining some of these very simple gadgets to create something a bit more complex.”
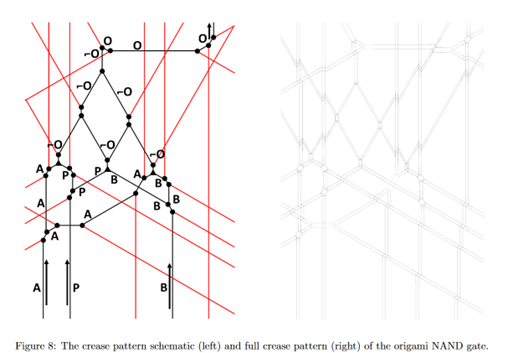
Illustration from An Original Turing Machine design, by Michael Assis
The paper by Assis investigates the geometry of a folded network that would create a triangular grid sufficient to implement a NAND gate in the hypothetical universal Turing machine. A NAND gate is one of many logical gates in a computer; logical gates are where the computer performs operations on binary inputs to produce a single output.
The logical complement of a NAND gate (deriving its name from NOT-AND) is the AND gate, such that the NAND gate contains none of the elements that are in the AND gate. When all of the inputs to a NAND gate are true, it outputs a result that says “false.” These gates provide important tests of computational logic and functional completeness.
The paper states that “Rather than implementing all types of logic gates, it is sufficient to implement a NAND gate, which is functionally complete, that is, all other logic gates can be constructed by cleverly connecting a series of NAND gates.” The paper also states that the NAND gates could also serve to store memory in the folded machine.
While Assis acknowledges that origami would be too fragile to operate in large machines, the principles could hold with sufficient technological advancements that would allow larger-scale application. The paper concludes, “rigidly foldable structures would need to be found which have more than one degree of freedom so that parts of the computer could be isolated from other parts in their folding. This requires the use of gadgets with vertices having more than four creases intersecting them.”
The future of computing applications depends on the evolution of computer memory capabilities.
The limitations that computer memory presents to data-intensive applications like generative AI are a cause for innovation that drives proposals like origami computation, the use of new materials, magnetic memory, or multi-dimensional layered memories.
Computing speed and data retention are not the only factors behind innovation in computing memory. The high cost of high-capacity memory chips and reliance on one company’s products is a major barrier to technological expansion. Most importantly, perhaps, the electrical requirements of current data retention methods are unsustainable and cause significant environmental damage, as we report in another article in this edition. A solution is required.
While the future direction of computer memory remains very much in question, the one certainty is that the incredibly creative capacity of the human mind will devise solutions that may be beyond current imagining.
Craving more information? Check out these recommended TQR articles:
- From Nature to Robots and Vice-Versa? Blurring the Lines Between the Real and the Virtual
- What Will a Recent Quantum Leap in Time Crystal Technology Reveal About the Elusive Nature of Time?
- Editing Our Human Selves: Will Quantum Computing’s Potential Increase the Risks or the Benefits?
- The Incredible Power of Shape: Fractals Connect Quantum Computers to the Human Body and the Cosmos
Your feedback helps us shape The Quantum Record just for you. Share your thoughts in our quick, 2-minute survey!
☞ Click here to complete our 2-minute survey